



The Findability Gap
If you’ve ever searched a knowledge base for content about a specific topic and ended up with a gazillion irrelevant results, you know how frustrating that can be. It gets even worse when you are trying to help a frustrated customer in real time and cannot find the information you need. That frustration quickly escalates. Anger leads to the dark side. Don’t go to the dark side.
At its core, findability is determined by the quality of indexing your application provides. If file contents are not indexed properly, they are essentially lost to the user, much like being adrift on the Island of Lost Toys. This issue is often worsened by inaccurate or missing filters, the “tags” we rely on to refine search results.
These filters help us retrieve what we actually want, not just what we initially requested. This is where taxonomies come into play. When a taxonomy is incomplete or lacks the foresight to be genuinely useful, those filters become ineffective. If that taxonomy is also confined within a proprietary system, the problem becomes even more frustrating.
Externalizing your taxonomy ensures that indexed content is supported by a robust, accurate set of tags that remain consistent across applications in your ecosystem. When a taxonomy is application specific and confined within a proprietary feature of a single system, those tags can only be interpreted within that application. Once your tags are isolated in a silo, they become effectively invisible to the rest of the organization.
Transitioning to Externalized Taxonomy Management means moving the naming and organizational logic out of your knowledge base or CMS and into a centralized knowledge hub designed specifically for governance and interoperability.
The Power of Structure
To understand why a centralized knowledge hub matters, we first need to examine how modern content is constructed.
Many organizations use XML (Extensible Markup Language) and DITA (Darwin Information Typing Architecture) to create structured content. Traditional content, such as a long PDF, is like a prepackaged frozen dinner. Everything is mixed together. If you want just the peas or, in my case, the cherry pie dessert, you have to dig through the entire tray.
Structured content is more like the shelves of a grocery store where every item is separated, organized, and clearly labeled. Every procedure, warning, or description becomes its own distinct component that can also carry its own metadata and tags.
Because XML and DITA break content into smaller reusable pieces, organizations need an accurate and efficient way to organize and track them. A taxonomy allows you to classify a content block as a Safety Warning, Update Notification, or Installation Procedure. Without a centralized taxonomy, you end up with a warehouse full of loose, unlabeled ingredients no one can find. Sort of like the junk drawer we all have in the kitchen. I have two, actually.
Establishing a Unified Data Language
Switching from application specific tags to an externalized model is similar to moving from proprietary charging cables to a universal standard.
By externalizing your taxonomy, you establish a Central Source of Truth: a governed set of tags that can be interpreted consistently across applications in your ecosystem. Dedicated tools such as Graphwise, PoolParty, Semantica, and similar platforms manage an organization’s shared vocabulary.
At MadCap, we believe the primary goal of content consumers is findability. In an externalized model, tags function like a GPS that works across platforms. Instead of guessing which proprietary tag corresponds to Customer Profile, an author can search for a governed concept that remains consistent throughout the ecosystem.
For example, a help desk agent may need to quickly locate instructions for updating an email address. A centralized taxonomy hub allows the search engine to understand that “email address” is related to a broader Customer Profile concept, helping guide the user to the correct documentation even if the exact keywords do not match.
In practice, the Customer Profile tag may work behind the scenes as part of the retrieval logic. Let’s break down how that interaction functions in a modern externalized taxonomy environment.
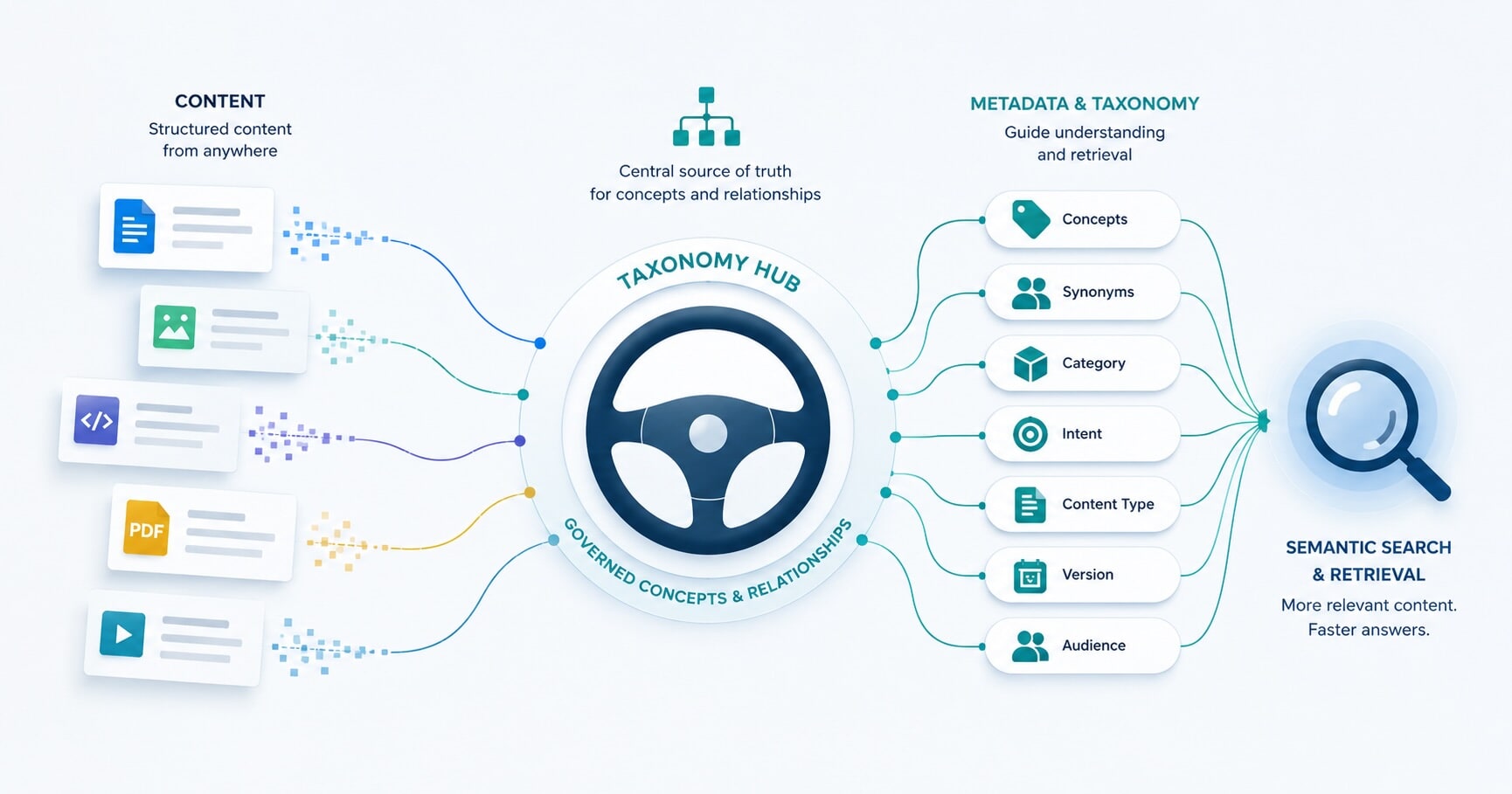
Vector Databases and the Role of Taxonomy
In environments where a CMS already uses a vector database such as MadCap SyndicateAI, the role of a centralized taxonomy hub shifts from acting as a manual filing cabinet to becoming a semantic anchor and governance layer.
A vector database provides the mathematical engine for semantic search, while an externalized taxonomy provides the human readable structure that makes those vectors more useful and governable.
Here’s how a centralized taxonomy and a vector based CMS work together to improve findability.
The Semantic Anchor for Embeddings
Vector embeddings are mathematical representations of the meaning of a chunk of content. However, semantic similarity alone can sometimes be imprecise. A centralized taxonomy acts as a stable reference point.
In a hybrid search model, which is the approach used by MadCap SyndicateAI, systems combine vector similarity with traditional metadata filtering. When a user searches for “email address,” vector search retrieves semantically related content, while the taxonomy provides governed tags such as Customer Profile that help narrow those results to the most relevant content.
Auto Tagging Through Semantic Matching
One of the most powerful uses of this dual system approach is automatic tag recommendation.
When content is ingested, the application generates a vector embedding. The system can then compare that embedding against embeddings associated with taxonomy concepts. If the document is semantically similar to concepts such as Software Version or Product Configuration, the CMS can recommend those tags to the author automatically.
This reduces manual tagging effort and improves consistency across systems.
Understanding User Intent
Even with vector databases, search can still fail if the user’s vocabulary differs from the documentation.
A centralized taxonomy can improve search through synonym mapping and query expansion before vector retrieval even begins. For example, the taxonomy may recognize that E-mail, Email, Electronic Mail, and Email Address all refer to the same concept.
The taxonomy can also associate related concepts such as User Profile or Account Settings, helping the vector search operate within a more accurate semantic context.
Why You Still Need an External Source of Truth
At this point, you might wonder why a taxonomy is still necessary if vector databases already understand semantic meaning.
The first reason is explainability. Vector databases are often black boxes. It can be difficult to understand why two pieces of content are considered related. A taxonomy provides a clear, human readable hierarchy that teams can govern and maintain.
The second reason is governance. You cannot realistically manage enterprise terminology by editing vector embeddings directly. But you can manage a centralized taxonomy and propagate those changes consistently across applications through API driven synchronization.
The Unified Architecture
In a modern architecture, the vector database acts as the engine for semantic retrieval, while the centralized taxonomy hub acts as the steering wheel that guides searches using governed terminology and business rules.
The taxonomy hub communicates with other systems through APIs that function as digital bridges across the ecosystem. Tools such as Graphwise or PoolParty maintain the master vocabulary, while connected systems such as CMS platforms, websites, and support portals reference those approved concepts.
When an author tags content, the CMS consults the taxonomy system for approved terminology, ensuring consistency across the entire ecosystem.
Adding Metadata to Your Metadata with SKOS and Semantic AI
Many proprietary systems treat tags as a flat list. Externalized taxonomy systems often use standards such as SKOS (Simple Knowledge Organization System), which gives metadata more depth and semantic structure.
SKOS allows tags to include:
- Preferred labels
- Synonyms
- Broader and narrower concepts
- Related concepts
- Scope notes
By converting both documents and taxonomy concepts into embeddings within a vector database, the system can compare the semantic meaning of new content against governed taxonomy concepts and recommend the most appropriate tags automatically.
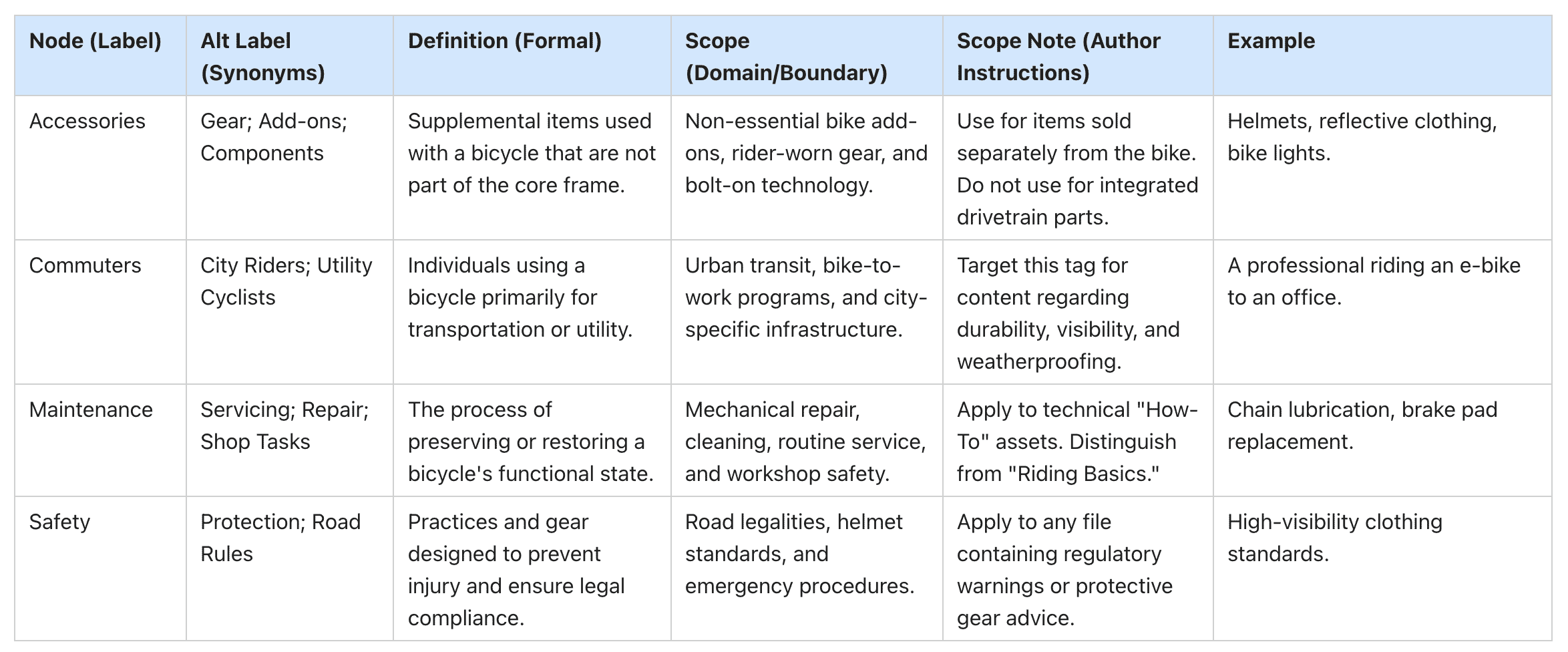
To illustrate how SKOS compliant metadata improves findability, let’s consider a fictional example from Stranti, Inc., a bicycle manufacturer managing a large library of technical documentation, product guides, and safety information.
The following table maps a simple flat tag structure to SKOS compliant metadata, including conceptual definitions, domain boundaries, and practical tagging guidance for content creators. The additional semantic definition improves both retrieval accuracy and confidence in how tags are applied across the ecosystem.
Key Implementation Considerations
When evaluating external taxonomy providers like those mentioned here, use these generalized concepts as your shopping checklist:

The Bottom Line
Moving away from a proprietary, application-specific taxonomy allows your organization to treat knowledge as a shared asset. By using a central tool to manage your "source of truth," you ensure that your DITA and XML content is always findable, accurately tagged, and ready for the next generation of semantic search.
At MadCap, we are making significant investments in our semantic analysis capabilities, including auto-tagging as described in this article, and laying the groundwork for MadCap SyndicateAI to achieve SKOS compliance.



