



This guest post was written by Kristen Kelleher, Director of Technical Publications at TIBCO Jaspersoft, where she will discuss how her team was able to integrate their MadCap Flare output with Drupal, and the lessons learned along the way.
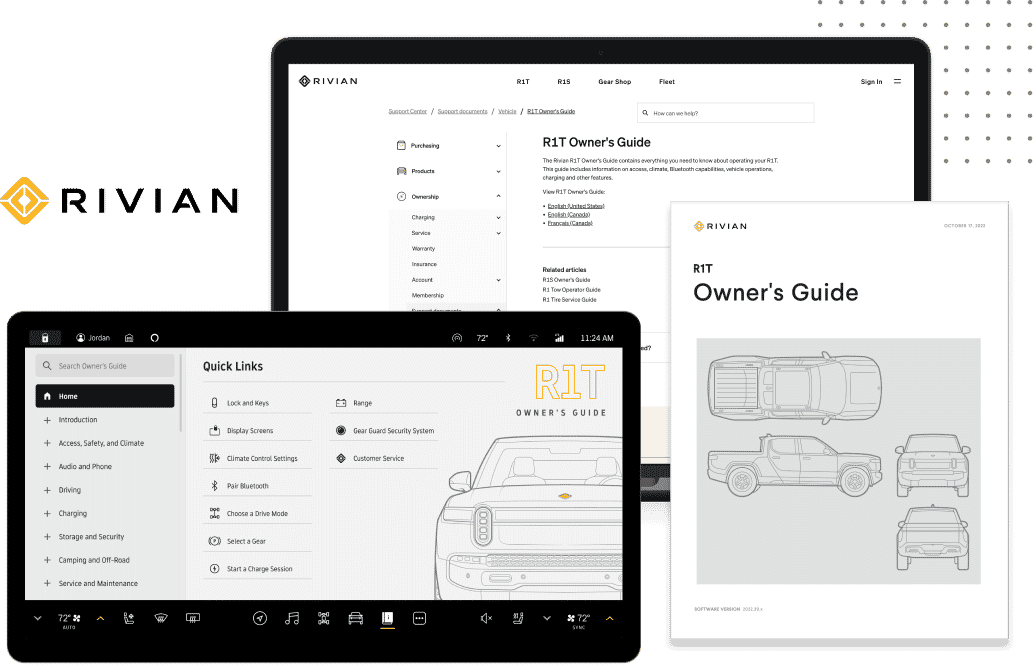
TIBCO’s Jaspersoft community documentation site integrates MadCap Flare output and Drupal to deliver content that’s easily indexable by search engines such as Google. This makes our documentation more available to our users, as well as generating leads for our digital marketing funnel and driving our subscription sales model.
The technical workings of our community documentation site rely on a custom Drupal module developed by our Web Team, who own and administer our Drupal implementation. In addition to HTML5 online help and PDF targets, our Flare projects include HTML5 targets that the Web Team’s custom module inspects, parses, and imports to construct a Drupal book.
Interpolating Flare Content into Drupal
We decided to deliver our content in Drupal’s book format in order to enable our marketing funnel, making Sales’ and Marketing’s lead generation goals a primary driver of the project.
Our lead generation process relies on people finding our website when they search for reporting and analytics solutions. The more people who find our website and register, the larger our pool of prospective customers. So we need broad, rich content that matches the terms our prospects search for. Our product documentation is one of the richest, most reliable sources of this content, so it needs to be exposed to search engines like Google, which indexes pages to provide their users with the most relevant results.
Generally, PDF isn’t easily indexable by search engines and feels clumsy and monolithic when returned as Google results. By contrast, the HTML5 content that we publish to Drupal is “crawlable” - that is, it’s in a format that search engines can index. The content is also organized into small sections that can be viewed independently, providing a better experience than clumsily returning an entire PDF.
For brevity, this post assumes that you’re familiar with both Flare’s HTML5 output and Drupal. There are many online resources about each, with active communities and robust help sites.
Tech Pubs Process
From a Tech Pubs perspective, we deliver standard HTML5 Flare output with a skin that matches our website’s CSS. Note that this skin is never used in Drupal; the skin is only used when the projects are viewed separately and serves in part to help us preview our work before it is imported into Drupal. Each package is consumed by the Web Team’s module, which parses the project and imports it as a Drupal book, preserving the hierarchical information in the table of contents and the index.
Note: When working in Flare, use styles consistently. Don’t veer from your templates or use in-line styles. Make sure the table of contents (and index) is well-structured and includes all of your content. Well-formed HTML and robust project metadata must be combined to successfully inject Flare content into Drupal.
Jasper Content as Developed in Flare and Injected into Drupal
Web Team Steps
Once the Flare targets are ready to publish, the Web Team:
- Validates the output package received from Tech Pubs to ensure it has the expected file structure. The output is then compressed into a ZIP archive (the file format expected by the Drupal module).
- Loads the book’s content and constructs a Drupal book using the custom module. The module builds the book’s table of contents from the metadata in the HTML5 target. If present, an index is also created.
- Smoke-tests the new book, looking for problems such as incorrect formatting, missing images, and broken hyperlinks. Occasionally we may run into problems and troubleshoot by first determining whether the problem is evident in the Flare output natively, or only in the imported Drupal book.
- Publishes the book for public consumption once it passes muster.
Mechanics of the Custom PHP Module
Let me preface this bit by encouraging you to explore newer options. If we had it to do over, we’d start with the Clean XHTML output, which wasn’t available at the time. While this still requires the custom Drupal module to recreate the content’s structure, we’d be using an output type intended to be ported into other tools. That would provide some assurance that the output format won’t change unexpectedly in later versions of Flare. As it stands, we are looking into adopting the Clean XHTML output to address this issue.
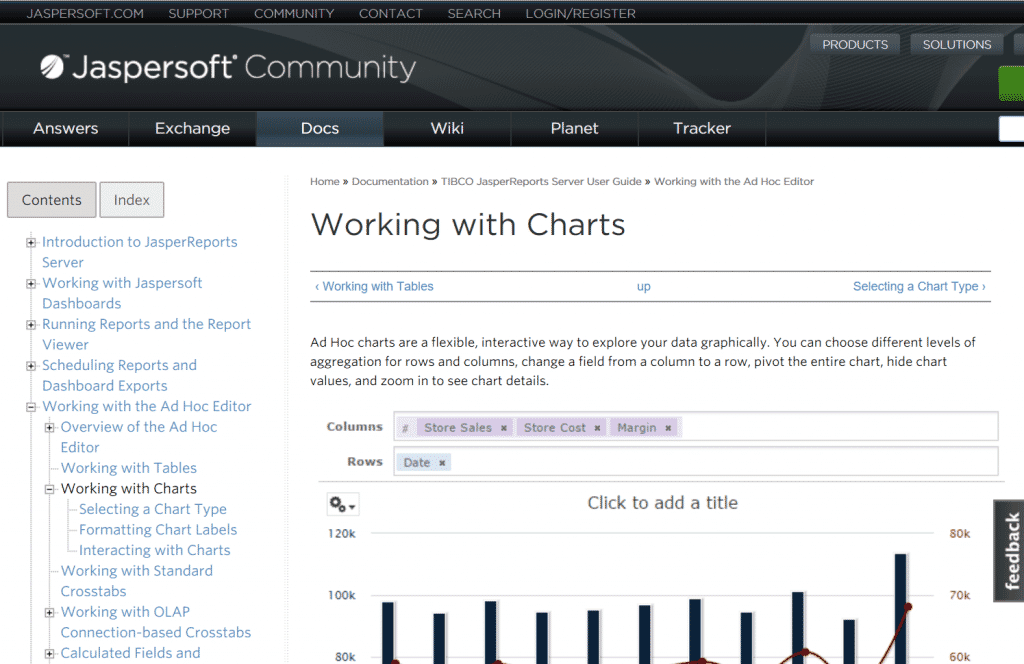
Several steps are involved in creating the Drupal project. The custom module inspects the project’s metadata files to determine how to process the book contents. For example, the Flare target’s table of contents (represented by ToC.xml and ToC_ChunkX.js) are inspected, aggregated, and used to create a multidimensional array that populates an XML file written to Drupal. This metadata is also used to create the nodes and book pages that compose the Drupal project that represents our book.
The index is created along similar lines; the module inspects the Flare Index.xml and IndexX.js files to create an array of terms and page links. That array is then used to write a new Drupal page that appears when users click the Index button.
In addition to creating the actual file structures in Drupal, the module iterates through our content files to clean them up. For example, the breadcrumbs generated by Flare are removed from the content pages, since Drupal’s built-in navigation provides identical functionality.
The custom PHP functions and regular expressions are complex; the module’s source code is 800 lines. In some cases, our code is particular to specific versions of Flare and Drupal, as well as being specific to our content. The functions and expressions you’d use will differ quite a bit. The general idea is to be sure to include all the relevant content, and then ‘clean up’ that content for proper display in Drupal.
During import, the module makes multiple passes through the output to:
- Interpret the project metadata to create the new Drupal directory structure, a table of contents, an index, and each topic and image in the book.
- Parses and imports the main body of each page.
- Parses and refactors links to images and other topics (to reflect the new book structure in Drupal).
- Removes unnecessary text or HTML.
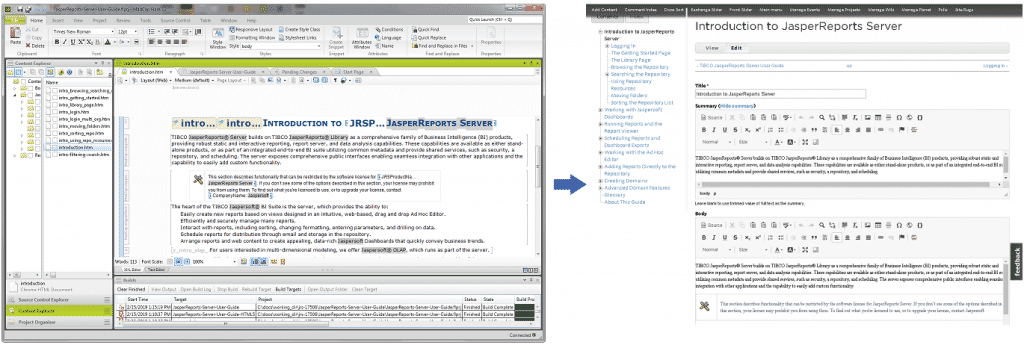
So, what’s left of a given page once the parser is done? In the Drupal book, each topic is stripped-down HTML; the figure below shows a topic opened for editing in Drupal. The structures that tie this page to others and define the book’s organization (the table of contents and index) also populate Drupal’s built-in page navigation elements.
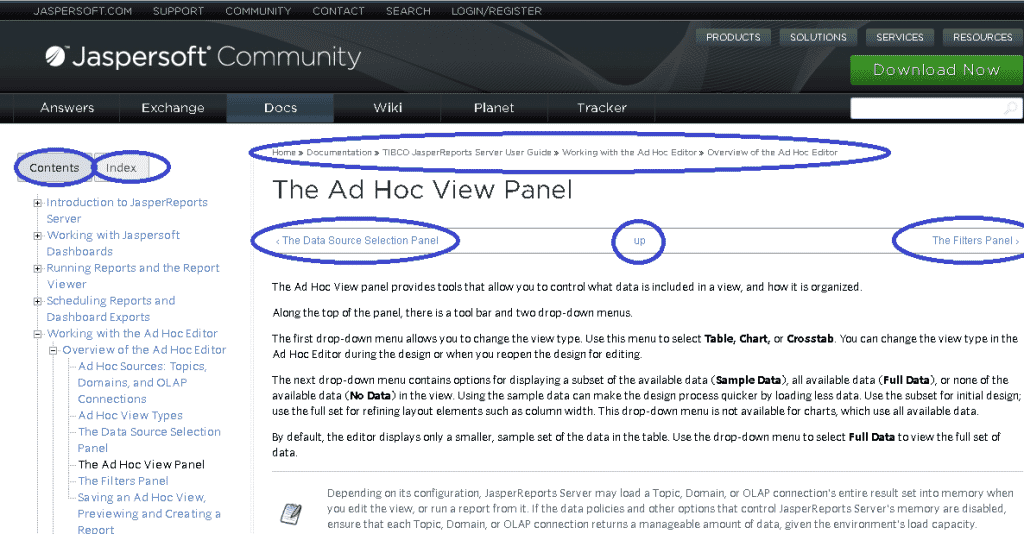
Flare Metadata Populates Drupal Navigation Elements
Benefits of Delivering through Drupal
Delivering our content through Drupal offers several benefits:
- Our users have unlimited admittance to our content and choose how to consume it as suits their tastes – either stored locally or hosted by us, through PDF, HTML5, or online help.
- Potential customers can learn about our products broadly and in-depth, and find answers to their questions directly from their browser window.
- Our Marketing and Sales teams benefit from increased lead flow through their funnel.
- Through page instrumentation and analytics, our sales engineers know what features and products their prospects have researched on our website and can start conversations with relevant demos.
- Our Support engineers can point clients to specific versions of documents when answering customer calls.
- As users of our own multi-channel publishing model, the tech writers can deliver their content to a wide audience in a variety of formats without the overwhelming overhead.
Beyond the Tools and Tech
Here are some broader considerations when delivering Flare content through Drupal:
- Build and nurture relationships. As a writer, you might not own the Drupal implementation that hosts your content. Devote some time and attention to building a relationship with the people who own Drupal. Both teams are one another’s customer in that each needs the other’s deliverable to succeed. Keep investing in this relationship to ensure it’s strong. In our case, user satisfaction and lead generation are everyone’s responsibility, so we prioritize working well together.
- Limit scope. You probably have some great ideas of how to present your content in Drupal. However, the more customized and feature-rich your design, the more complicated the projects and process will be. Decide which ideas are most important, decide which are easy to implement, and start with the items that meet both criteria. You might never get to every last feature you envisioned, and that may be for the best.
- Consider SEO. Search engine optimization is the practice of refining content to maximize your pages' rankings in search results. It's an art and science of its own that takes time and manpower, but can be well worth the effort.
- Work iteratively. Start with a small project and ensure that you can parse and import it properly. As you add other books, refine the import step to address any new issues, and ensure you can import newer versions of your book as well. Try not to bite off more than you can chew.
- If the process seems overly complicated, chalk it up to early adopters. We achieved our ends with the tools in hand in 2014 (Flare HTML5 output and Drupal), knowing we’d eventually hit some bumps. There’s no good time to take the plunge, and there’s always a reason not to. So decide where to get started and work through your doc set.
- Investigate using Clean XHTML. Instead of HTML5 as the target to import into Drupal, try this newer target type, along with one of the community-contributed Drupal book import modules, such as XiNGDigital’s HTML Import module. If you come up with something cool, let the community know!
Picking a New Direction
Writing is iterative, and change is an integral part of the documentation process. We’re currently planning a major overhaul to our community site, and adopting the Clean XHTML output in hopes of simplifying our lives. We’re early in the project, but we hope this format takes less parsing. We shall see!
In the long term, we’re looking at ways to streamline the creation of API docs by adding Swagger to the mix. We’re just wading into this area; others are already creating interesting projects. I don’t have a roadmap for this Flare journey, but our experience delivering output through Drupal tells me we can figure this out, too.



