




Organizations are betting big on AI. New platforms, new budgets, new executive mandates to "become an AI-first company." And somewhere in the middle of all that momentum, someone points to RAG as the answer to delivering reliable, company-specific AI responses.
RAG is a genuinely good idea. But it only works if the content it retrieves is any good.
And in most enterprises, content lives across systems that have each been maintained independently for years. Documentation in one place. Training content in another. Support articles somewhere else. Each one updated on its own schedule, each one gradually drifting from the others.
Drop a RAG system on top of that environment, and it will not solve the problem. It will retrieve from it. Confidently. And at scale.
The good news is, building a content foundation those systems depend on is more achievable than most teams realize.
What Is RAG?
Good question, and worth a quick answer before we go further.
Retrieval-augmented generation, or RAG, is how enterprises make sure their AI only says what they want it to say.
RAG connects your AI to your own content sources. When someone asks a question, the system retrieves the most relevant content from your approved knowledge base and builds the response. Your documentation. Your policies. Your approved answers.
You do not need to train a custom model from scratch. That is what makes RAG so valuable for enterprise AI. You are not hoping the model gets it right. You are controlling exactly what it can access and what it can say.
So Why Does RAG So Often Disappoint?
Here is a scenario that plays out more often than anyone likes to admit.
A team spends months implementing a RAG-powered AI assistant. The model is solid. The interface is clean. Leadership is excited. And then it goes live and starts returning answers that are outdated, inconsistent, or just plain wrong.
The instinct is to blame the model. Tune it more. Swap it out. Try a different architecture.
But the model is usually not the problem.
Most enterprises store knowledge across a sprawl of platforms: product documentation systems, support knowledge bases, learning management systems, internal wikis, customer-facing help centers. Each one has its own copy of overlapping information. Each one gets updated on its own schedule by its own team. Over time, they drift. Language changes in one place but not another. A version gets updated here but not there. Metadata becomes inconsistent, incomplete, or just ignored.
When AI reaches into that environment, it finds competing versions of the same knowledge and has no way to know which one is right. It picks what it finds and builds a response. The answer looks authoritative. It may not be.
This is not a RAG failure. It is a content governance gap. And it is entirely fixable.
Hallucination vs. Retrieval
When AI confidently produces a wrong answer, the word everyone reaches for is hallucination. The model made something up. Time to find a better model.
But in enterprise deployments, genuine hallucination is less common than people think. What looks like a hallucination is often something different: the model retrieved accurately from a fragmented content environment and faithfully reflected the inconsistency it found.
The model did its job. The content environment failed.
This distinction matters because it points to a completely different fix. When AI returns a wrong answer, look at the content before you look at the model. That is usually where the fix lives, and it is more straightforward than most teams expect.
If the model is retrieving from ungoverned content, you need better content governance.
The Fragmentation Problem Is Older Than AI
Content teams have been dealing with fragmentation for a long time. The frustration of updating a product feature and then having to chase that change across documentation, training materials, support articles, and the help center is not new. It has always been tedious, error-prone, and expensive in terms of time.
What is new is the consequence.
When a human reads an outdated support article, they might notice something feels off. They might search for a more recent version. They exercise judgment. AI does not. It retrieves, constructs, and delivers with equal confidence regardless of whether the source material is three weeks old or three years old.
A single missed update can now surface across every AI-powered touchpoint in your customer experience simultaneously. That is a different kind of exposure than a stale document sitting in a knowledge base.
AI did not create the fragmentation problem. It exposed it and raised the stakes for solving it.
Solving it requires more than better authoring discipline. It requires controlling how content moves across systems after it is published. That is exactly the problem MadCap Syndicate was built to solve, and we will get into how shortly.
AI Readiness Is Not a Technology Problem
This is the part where a lot of AI initiatives go sideways.
Teams spend months evaluating models, selecting platforms, designing conversational interfaces, and building integration pipelines. All of that work is real and necessary. But it is infrastructure built on top of a knowledge foundation that nobody stopped to assess.
AI performs best when content is structured, consistent, and governed. Clear component relationships, standardized terminology, and well-maintained metadata give retrieval systems something reliable to work with. Modern structured authoring environments, like those used in professional technical documentation, support this well. Content is built in reusable components. Metadata is applied consistently. Outputs maintain the same language and formatting across contexts.
But here is the catch. Even perfectly structured content becomes unreliable the moment it is copied into another system and begins to evolve independently. Structure at the authoring stage is necessary. It is not sufficient.
The question is not just how well your content is written. It is how well it is governed after it leaves the authoring environment. That is where most organizations have the biggest gap, and where the most important work is waiting to be done.
Good Authoring Governance Is Not Enough
Most content teams have solid authoring governance in place. There are review workflows, approval processes, version histories. Someone signs off before something gets published. The problem is that governance usually stops at publication.
After content ships, it gets copied. The same product description ends up in the documentation portal, the onboarding module, the support knowledge base, and the AI assistant's retrieval pool. Each copy starts its life identical. Then someone updates the documentation but forgets the support article. Someone revises the onboarding module but does not touch the portal. Six months later, four systems are confidently presenting four slightly different versions of the same information.
For a human reader, that is confusing and frustrating. For an AI system, it is destabilizing. There is no way for the model to distinguish between versions. It retrieves what it finds.
Governance that ends at publication only covers half the problem.
The Fix: Govern the Flow, Not Just the Source
The solution is not to write better content. Most teams are already doing that. The solution is to change how content moves.
Instead of copying content into downstream systems and hoping everyone keeps their copy current, the right model is to govern content once and distribute it automatically to every system that needs it. One authoritative, trusted source. Controlled distribution. Every connected platform always receives the latest approved version.
This is content syndication, and it is what makes AI governance actually work in practice.
There are no parallel copies to chase, no manual updates to coordinate across a dozen platforms, no region that quietly keeps running on last quarter's information. When content expires, it is removed everywhere simultaneously. The entire ecosystem stays in sync because it draws from the same source.
For AI systems, this is the difference between retrieving from a stable, trusted foundation and retrieving from a fragmented collection of documents at various points in their lifecycle. The first produces reliable responses. The second produces the kind of confident inaccuracy that erodes customer trust fast.
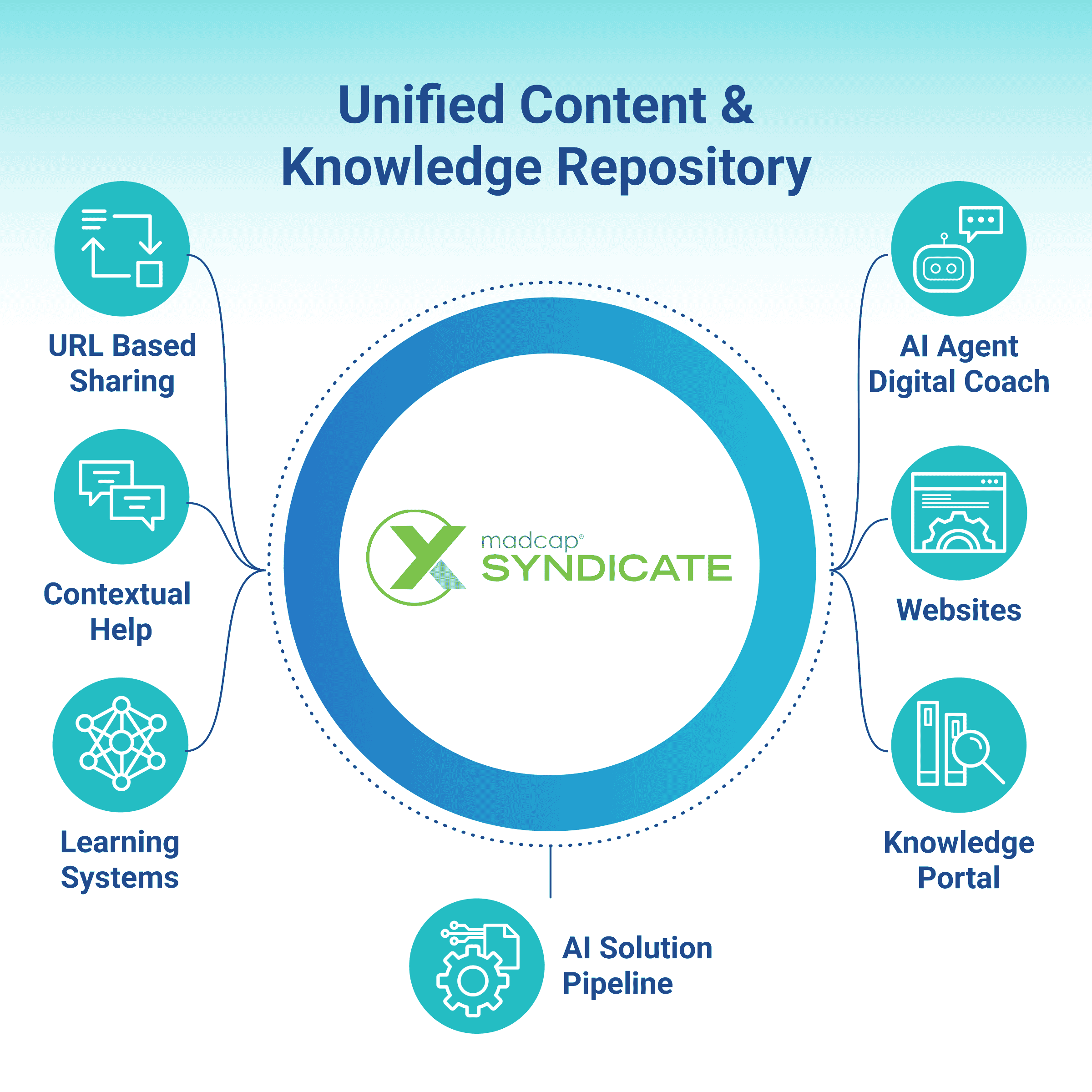
How MadCap Syndicate Makes This Real
MadCap Syndicate is built specifically to be the governed distribution layer your enterprise content ecosystem is missing.
It sits between your authoring environment and every downstream system that consumes content: documentation portals, LMS platforms, support knowledge bases, customer-facing help centers, and AI retrieval systems. Content is authored and approved once, then Syndicate controls how it flows outward. Every connected system receives the same trusted, current version. Nothing is copied manually. Nothing drifts.
When a product changes and documentation is updated, Syndicate propagates that change automatically across every connected platform. Your support team, your training environment, your AI assistant, and your customer portal all reflect the update at the same time. There is no lag, no version mismatch, no market or department running on outdated information.
Permissions are enforced at the distribution layer, not just at the authoring stage. Expired content is removed from every endpoint simultaneously. Version history is traceable and auditable. When a regulator or an internal audit asks what content your AI was retrieving on a given date, you have a clear answer.
For documentation and knowledge teams, this changes the nature of the work. Instead of spending time chasing updates across systems, they govern a single source that serves everywhere. Instead of worrying about which copy is current, they know. Instead of hoping their AI retrieval pool is clean, they control it.
The best part is that Syndicate does not require you to replace your existing tech stack. Your LMS stays. Your documentation platform stays. Your support system stays. Syndicate connects them under a governed distribution model so they all work from the same truth.
That is what makes RAG reliable. Not a better model. A better foundation.
Ready to Build the Foundation?
See how MadCap Syndicate governs knowledge distribution across your enterprise so every AI response starts from a trusted source.